感知机
学习笔记
-
感知机是二类分类的线性模型,属于判别模型
-
感知机学习旨在求出将训练数据进行线性划分的分离超平面。是神经网络和支持向量机的基础
-
损失函数选择
- 损失函数的一个自然选择是误分类点的总数,但是,这样的损失函数不是参数的连续可导函数,不易优化
- 损失函数的另一个选择是误分类点到超平面的总距离,这正是感知机所采用的
-
感知机学习的经验风险函数(损失函数)
其中是误分类点的集合,给定训练数据集,损失函数是和的连续可导函数
原始形式算法
输入:训练数据集
输出:
选取初值
训练集中选取数据
如果
转至(2),直至训练集中没有误分类点
- 这个是原始形式中的迭代公式,可以对补1,将和合并在一起,合在一起的这个叫做扩充权重向量
对偶形式算法
- 对偶形式的基本思想是将和表示为实例和标记的线性组合的形式,通过求解其系数而求得和。
输入:
输出:
训练集中选取数据
如果
- 转至(2),直至训练集中没有误分类点
-
Gram matrix
对偶形式中,训练实例仅以内积的形式出现。
为了方便可预先将训练集中的实例间的内积计算出来并以矩阵的形式存储,这个矩阵就是所谓的Gram矩阵
习题解答
- 2.1 Minsky 与 Papert 指出:感知机因为是线性模型,所以不能表示复杂的函数,如异或 (XOR)。验证感知机为什么不能表示异或。
- 我们显然无法使用一条直线将两类样本划分,异或问题是线性不可分的。
- 可以借助下面动图理解

- 2.2 模仿例题 2.1,构建从训练数据求解感知机模型的例子。
- 感知机的训练过程如上所述,取与原例题相同的数据,计算出不同的结果
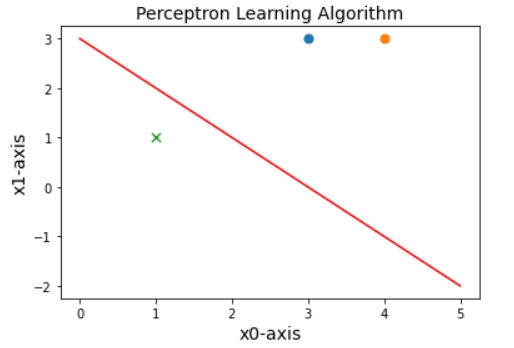
- x = [3 3; 4 3; 1 1];
y = [1; 1; -1]; - 根据程序运行可得:
- eg1:
误分类点为: [3 3] 此时的w和b为: [[0.][0.]] 0
误分类点为: [1 1] 此时的w和b为: [[3.][3.]] 1
误分类点为: [1 1] 此时的w和b为: [[2.][2.]] 0
误分类点为: [1 1] 此时的w和b为: [[1.][1.]] -1
误分类点为: [3 3] 此时的w和b为: [[0.][0.]] -2
误分类点为: [1 1] 此时的w和b为: [[3.][3.]] -1
误分类点为: [1 1] 此时的w和b为: [[2. [2.]] -2
最终训练得到的w和b为: [[1.] [1.]] -3
即
- eg2:
误分类点为: [1 1] 此时的w和b为: [[0.] [0.]] 0
误分类点为: [4 3] 此时的w和b为: [[-1.] [-1.]] -1
误分类点为: [1 1] 此时的w和b为: [[3.] [2.]] 0
误分类点为: [1 1] 此时的w和b为: [[2.] [1.]] -1
最终训练得到的w和b为: [[1.] [0.]] -2
即
实例
import numpy as np
import matplotlib.pyplot as plt
#1、创建数据集
def createdata():
samples=np.array([[3,3],[4,3],[1,1]])
labels=np.array([1,1,-1])
return samples,labels
#训练感知机模型
class Perceptron:
def __init__(self,x,y,a=1):
self.x=x
self.y=y
self.w=np.zeros((x.shape[1],1))#初始化权重,w1,w2均为0
self.b=0
self.a=1#学习率
self.numsamples=self.x.shape[0]
self.numfeatures=self.x.shape[1]
def sign(self,w,b,x):
y=np.dot(x,w)+b
return int(y)
def update(self,label_i,data_i):
tmp=label_i*self.a*data_i
tmp=tmp.reshape(self.w.shape)
#更新w和b
self.w+=tmp
self.b+=label_i*self.a
def train(self):
isFind=False
while not isFind:
count=0
for i in range(self.numsamples):
tmpY=self.sign(self.w,self.b,self.x[i,:])
if tmpY*self.y[i]<=0:
#如果是一个误分类实例点
print('误分类点为:',self.x[i,:],'此时的w和b为:',self.w,self.b)
count+=1
self.update(self.y[i],self.x[i,:])
if count==0:
print('最终训练得到的w和b为:',self.w,self.b)
isFind=True
return self.w,self.b
#画图描绘
class Picture:
def __init__(self,data,w,b):
self.b=b
self.w=w
plt.figure(1)
plt.title('Perceptron Learning Algorithm',size=14)
plt.xlabel('x0-axis',size=14)
plt.ylabel('x1-axis',size=14)
xData=np.linspace(0,5,100)
yData=self.expression(xData)
plt.plot(xData,yData,color='r',label='sample data')
plt.scatter(data[0][0],data[0][1],s=50)
plt.scatter(data[1][0],data[1][1],s=50)
plt.scatter(data[2][0],data[2][1],s=50,marker='x')
plt.savefig('2d.png',dpi=75)
def expression(self,x):
y=(-self.b-self.w[0]*x)/self.w[1]#注意在此,把x0,x1当做两个坐标轴,把x1当做自变量,x2为因变量
return y
def Show(self):
plt.show()
if __name__ == '__main__':
samples,labels=createdata()
myperceptron=Perceptron(x=samples,y=labels)
weights,bias=myperceptron.train()
Picture=Picture(samples,weights,bias)
Picture.Show()