A City-Wide Crowdsourcing Delivery System with Reinforcement Learning
背景
众包交付系统
众包交付的实际因素
- 时间限制:订单到顾客接受货物的时间具有限制
- 多跳:从送货站到收货站存在多跳现象。
- 利润和价格的设置:作为参数影响。
工作模式
本文设想一个实用的公共交通为基础的搭便车交付如下。搭车送货系统由图1所示的四部分组成: 云服务器、邮箱、客户端和客户端。邮箱通过 Wi-Fi 或者蜂窝网络连接到云服务器。现成的盒子产品已经开发和部署作为智能储物柜在公共领域:
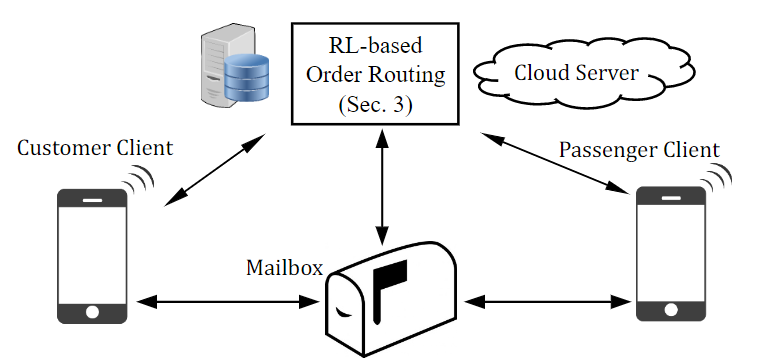
具体注意:
- 客户(发送方)将包放在他/她的原始站的邮箱阵列的邮箱中,然后在客户端中输入包的目的地。客户可选择两小时、半天(6小时)或当日保修期服务,但价格不同。
- 服务器根据所有包和环境的及时信息(如时间、天气、供需比),决定所有包跨所有站点的下一跳。
- 当参与的乘客来到一个邮箱阵列时,她可以在智能手机上报告她的目的地。根据乘客的输入和邮箱阵列中现有包裹的预定路线,系统决定哪些包裹由乘客携带。多个包裹将被发送给乘客,如果他们共享同一个下一跳,这不是超出乘客的能力。具体措施就是下面要讲的TA-Aware RL-Dispatch算法
- 当旅客到达目的地(不一定是包裹的目的地)时,他/她将包裹放入指定的邮箱,并声称任务已经完成。另一名旅客会前来重复上述程序,直至包裹抵达目的地。旅客只需在自己跳跃的源头和目的地拿起包裹,不需要绕道而行。因此,交付是纯粹的搭便车,乘客的路线或行为没有改变。
- 当包到达目的地时,客户(接收方)得到通知并打开邮箱获取包。如果超过时间限制,平台将对客户进行赔偿,即如果包裹超过时间保证,客户将获得退款。
以利润为导向的调度模型
针对云服务器上的订单分发问题,考虑到包的时间约束,使平台利润最大化。首先介绍了一个具有实际因素的利润模型; 然后展示了ETA模块的细节来模拟估计站之间的交付时间; 最后,设计了一个强化学习算法来解决包装工的路由问题。
利润模型
最大化利润:
为包的个数,是顾客采用的配送方式,是递送包裹经过的跳数,是支付给乘客第个包裹,第跳的费用。为为满足时间要求的包裹数目。
要最大化利润就要每个包更少的跳数,以及更少的过期(违约)包。也就是平衡。因此文章的重点是选取ETA 模型来评估不同站对(station pair)之间的旅行时间,和一个 RL 模型来选择最优路径。在包调度中,我们主要关注如何减少每个包所需的跳数,同时使更多的包在时间限制内交付
ETA模块
ETA是任何两个站点之间的包裹估计递送估计情况,使用ETA模块对交付时间信息进行显式聚合和建模,以缩小动作空间,提高学习性能。
配送时间被分为等待时间waiting time和运行时间running time,总体配送时间表示为:
等待时间是指包裹在源站或中转站的邮箱中的时间,运行时间是指乘客在移动中携带包裹的时间。是指在第个中转站的等待时间,是指到第个中转站的运行时间。为总共的跳数。
高斯分布
引进分位点函数
保证真实配送时间小于或等于估计时间的概率为,(为订单及时率)
waiting time
包裹到下一站站的等待时间为从包裹放置到乘客刷卡进入下一站的时间。 这里我有一个问题,是根据什么样的数据集进行计算的呢?目前的数据是从某个点到目的地的位置相信和出发到达信息,以及订单数目信息
将一天化为24个时隙,每个时隙有固定的和并采用极大似然估计得到估计量:
论文通过了Kolmogorov-Smirnov检验。
乘客意愿
本文利用参与率指标来模拟乘客愿意接受包裹的意愿。
so we use the first arrival passenger between the station pair under the participate rate to estimate the waiting time. Therefore, the estimation of the waiting time is independent of the dispatching policy.这句话没理解
running time
运行时间是根据乘客刷卡进入和刷卡离开的时间来计算的,这一点我觉得奇怪:没有刷卡数据,只有订单目的地和起始地点的位置数据 在固定时间间隔和间隔率的情况下,特定OD对(数据集)的运行时间和等待时间可以用高斯函数拟合,并用深圳地铁一个月数据的 K-S 检验进行了验证。用不同的参与率计算城市公共交通的ETA结果,将其存储为一个4-D 张量 ,而和这里我有些疑问,函数是怎么确定的,整篇文章没看到是估计等待时间的高斯参数,和是估计运行时间的高斯参数,分别在站点和之间,是参与率,是当前时段。
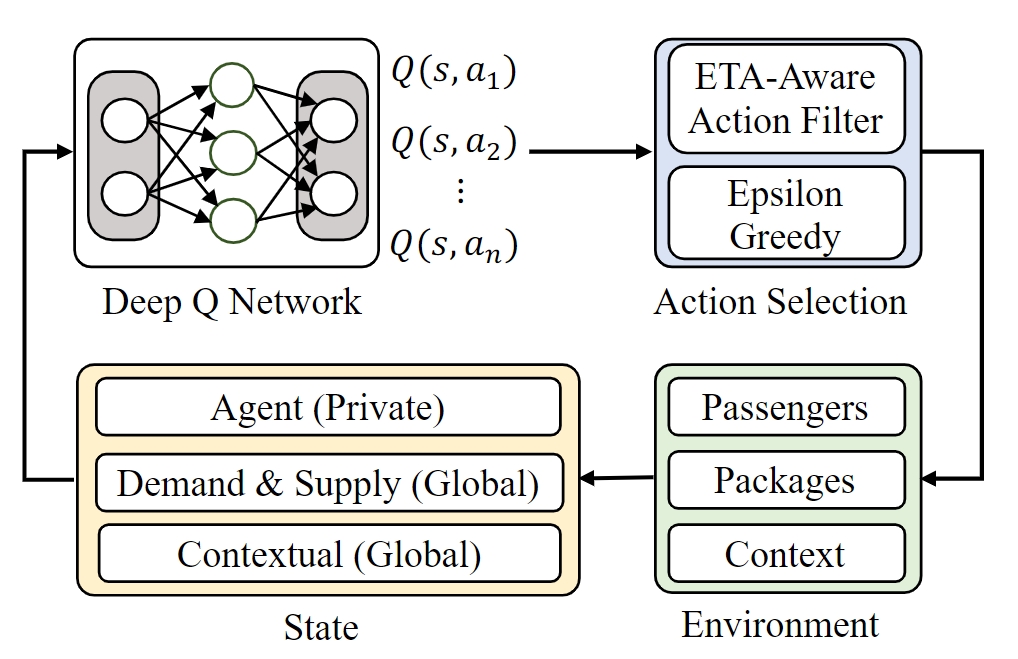
ETA-Aware RL-Dispatch算法
我们使用深rl方法来学习来自大规模历史传输数据和包数据的每个包的最佳路线,不同的价格设置(和)和环境因素(天气,时间,供应和需求)。ETA感知的动作过滤器旨在消除基于ETA的不可行的动作,以加速离线培训并改善在线路由。
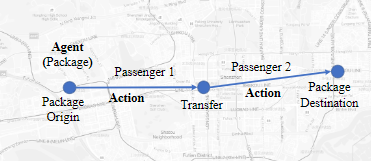
随着包裹和旅客在现实世界中的动态状态,包裹路由问题自然是一个序贯决策问题。在我们的问题设置中,如图2所示,代理人是系统中的包裹。决策中心充当元代理,以集中的方式为所有包做出决策。元代理在连续的时间段(例如,每个包5分钟)做出决定(例如,为每个包选择下一跳) ,并预测未来几个小时的总收入回报(例如,平台利润)。环境是包裹和乘客在系统中移动,以及一些环境,如天气。RL 的组成部分定义如下。
- 代理:我们认为每一个包装都是一个代理商。决策中心作为一个元代理,为所有代理作出决策,从而使各站之间的所有包的路由可以被了解并在各站的所有包之间共享。
- 状态空间:在每个时间段有两个状态:global state和private states. 我们使用供应和需求信息作为状态特性来进一步模拟实际应用程序,因此global state又分为:
- Demand states:所有站点的等待包裹的一维分布,所有站对中正在递送的包装的2维分布()。
- Supply states:所有站点进站乘客的一维分布,所有站对中正在通勤乘客的二维分布()
- Contextual states:该信息表示为天气,日期,平日和时间。
- 动作空间:单个代理的操作指定包的下一跳,特别是包应该在所有站之间传送的下一站。
- 奖励函数:针对总利润表达设置奖励函数。奖励函数在包到达目的地之前设置为0,否则设置为:
是一个指示函数,如果包裹没有超时,则在包裹到达目的地之前,奖励不计算在内。在满足时间约束的前提下,通过奖励函数使算法选择跳数最小的路由。也就是不追求每个订单时间最短,只要在时间限制之内即可。
- 动作值计算:动作值
是值按照策略下,当前状态采取动作时获得的潜在期望价值。
其中为t时刻潜在价值
由于每次的代理与环境交互并不一定将所有值填完,因此在基于价值的无模型强化学习方法中,动作价值函数使用函数逼近器来表示,比如神经网络。这里的DQN方法也是利用这一点,让是一个带有参数的近似动作值函数,简而言之,利用神经网络训练
。在每次迭代中,DQN 使用以下损失函数更新参数:
- ETA感知动作过滤
由于行动是包装的下一个站选择,因此在城市中的数百个运输站,动作空间很大。大型动作空间导致训练中的缓慢收敛,并影响路由性能。鉴于我们离线收集的ETA信息,我们在动作过滤过程中使用了此先前知识,以加速培训并提供交货时间的统计保证。在过滤器中,动作的潜在选择概率为:
是从当前站到目的地的预计到达时间(由ETA算出),是包裹约定的到达时间。
是由动作决定的下一站。如果下一站就是目的站,则:
我们基于ETA的结果可求出每个时段,每个起始点的拟合参数,计算相应的时间:
为置信度,参数的选择会影响到交货率,从而影响到利润。较大的值会提高交货率(即准时率),但也会排除一些潜在的低成本路线。特别指出,当为负数时,也就是当前以及过期了,包裹将优先发货。
算法伪代码:

在模型训练过程中,我们构建了能够基于乘客数据、包数据和上下文数据恢复环境演化的模拟器。
仿真
本文使用了75%的地铁/包裹递送数据来建立模拟器,25%的数据用于评估。对于每个包都有三个状态: “等待”、“在路上”和“交付”。“ Wating”意思是一个包裹正在原点站或者换乘站的邮箱中等待。“在途中”是指一个包裹已经被旅客提起,并且正在运送到中转站或目的地的过程中。“投递”是指最后一次飞行的旅客已将包裹投递到目的地。例如,对于带有两个跃点的包,它的状态顺序应该是“ Waiting”、“ On the way”、“ Waiting”、“ On the way”、“ Delivered”。为了模拟一个只有部分乘客愿意携带包裹的现实世界场景,我们通过随机选择相应的乘客百分比来设置不同的参与率,为一个包裹递送。
对于调度系统的每个时间间隔,模拟器的工作方式为:
- Add new packages: 检查包数据集,并将前一时刻中出现的包添加到包集中,并将其状态设置为“Waiting”。
- Update “On the way” packages’ states: 对于“在路上”的包裹,在处查看相应的旅客数据,找到到达中转站或目的地的包裹,并将包裹的状态设置为“等候”或“送达”。
- Package dispatching: 对于所有未分发的“等待”包,使用 ETA-Aware RL-Dispatch 决定包的下一跳。
离发送者和接收者最近的位置的地铁站被分配为源站和目标站。在时间限制方面,我们为每个包裹分别设定时间限制,由1至8小时不等,以确保当日送达。



